In the first post I built Glimmer as a simple HTTP POST beacon and wrote detection rules to catch it. In the second post I researched more covert channels to communicate over and additional detection rules in YARA and Suricata. This post covers exploring the eBPF detection surface with Tetragon and building raw sockets and packets.
This post is about where endpoint network visibility breaks when you only watch the standard socket paths, and how much deeper you need to go to close (some of) those gaps. I’m going to run Glimmer (my Rust C2 framework) against some example Tetragon policies, find the gaps, extend the policy to close them, extend Glimmer with new techniques that evade the latest policy, repeat.
Along the way I’ll show why extending detection is rarely as simple as “add a hook”, the kernel’s network dispatch has structure that matters for what you catch.
Tetragon Detection
Cilium (maintainer of Tetragon) provides an extensive policylibrary and tracingpolicy directory with examples. The examples are starting points to review, customize, and deploy based on your environment. For this post, I loaded a broad set of the example policies to represent a reasonable “out of the box after initial setup” deployment. I removed the filters designed to keep volume manageable that filter to 127.0.0.1.
With the policies implemented and Tetragon started, I can run Glimmer while watching the nice emoji output from tetra getevents -o compact:
🚀 process devbox.int <path>/beacon
🧬 loader devbox.int /usr/bin/bash 77390419ffd7d7d23ab5676126daff3f16dbb6e0 /usr/lib64/ld-linux-x86-64.so.2
🧬 loader devbox.int <path>/beacon 4cc1806d514aae73670a16a837969d432d752c10 /usr/lib64/libgcc_s-15-20260123.so.1
🧬 loader devbox.int <path>/beacon da77d7e1bfae0d0e0a14dfba87caabe462dedba8 /usr/lib64/libm.so.6
🧬 loader devbox.int <path>/beacon 92b5376d35bb29c098175948cf3e7cbcae3aeae1 /usr/lib64/libc.so.6
❓ syscall devbox.int <path>/beacon sk_alloc
❓ syscall devbox.int <path>/beacon ip_output
❓ syscall devbox.int <path>/beacon __sk_free
❓ syscall devbox.int <path>/beacon sk_alloc
🔌 connect devbox.int <path>/beacon tcp 127.0.0.1:47370 -> 127.0.0.1:8080
📤 sendmsg devbox.int <path>/beacon tcp 127.0.0.1:47370 -> 127.0.0.1:8080 bytes 774
🧹 close devbox.int <path>/beacon tcp 127.0.0.1:47370 -> 127.0.0.1:8080
❓ syscall devbox.int <path>/beacon __sk_free
Breaking it down line by line:
🚀 process- initial process execution, captured by theexecvesyscall hook🧬 loader- four dynamically linked libraries loaded, captured viaperf events❓ syscall sk_alloc- socket allocation for DNS query connection❓ syscall ip_output- DNS query being sent❓ syscall __sk_free- socket for DNS query being released🔌 connect- TCP connect to the beacon receiver, captured by thetcp_connectkprobe📤 sendmsg- HTTP POST body (774 bytes) written to the socket, captured by thetcp_sendmsgkprobe🧹 close- socket closed after response received, captured by thetcp_closekprobe❓ syscall __sk_free- socket being released after being closed
Glimmer uses direct assembly syscalls (SYS_write, SYS_open, SYS_connect, SYS_socket) rather than calling libc wrappers like write() or connect(). This bypasses any libc-based detection like uprobes attached to functions in libc.so.6 because those functions never execute. The kernel kprobes still fire (tcp_sendmsg, tcp_connect, tcp_close, sys_socket) because the kernel’s dispatch tree sees the same function calls regardless of whether userspace arrived via libc functions like write(), send(), sendto(), sendmsg(), etc or a raw syscall.
Extending Tetragon Policies
These policies give us a great starting point but leave visibility gaps in UDP traffic and socket lifecycle events. Next step is extending the policy set to cover:
- Socket creation with family/type/protocol extraction: hook
sys_socketand extract the arguments so we can distinguish the socket family (AF_INET from AF_UNIX from AF_PACKET), and type (SOCK_STREAM from SOCK_DGRAM from SOCK_RAW). - UDP send/receive: hook
udp_sendmsgandudp_recvmsgfor socket-layer UDP traffic, plusskb_consume_udpfor packet-level receive visibility (which catches UDP traffic even when userspace uses non-standard delivery paths). - TCP receive: hook
tcp_recvmsgto pair with the existingtcp_sendmsgcoverage. - UDP and TCP connect: hook
udp_connectandtcp_connectfor the family-specific connect paths. - DNS resolver uprobes: hook
getaddrinfo,gethostbyname,getnameinfo,gethostbyaddr,res_query,res_search,res_sendin libc for applications that use the standard resolver APIs. This gives us userspace-level DNS visibility that complements the packet-level UDP hooks - a dedicated DNS post will cover why both matter in the future. - Connect visibility at multiple layers: hook
sys_connect(filtered to AF_INET and AF_INET6) for the syscall entry
I also made a new parser that keeps the Tetragon emoji output style and reads the tetra getevents -o json output for more events than the built-in display handles. I will look into the current parser soon and see what it would take to add these to it directly.
Since tetra getevents -o compact (above output) doesn’t include formatters for most of these kprobes they show as ❓ syscall. I wrote a custom parser that reads the full JSON stream and formats each kprobe type with relevant fields. Source is on GitHub. I’ll look into extending the existing compact formatter.
Running Glimmer again with the extended policy and custom parser:
🚀 exec /bin/bash -> <path>/beacon
🧦 sys-sock <path>/beacon AF_INET DGRAM UDP
🔌 sys-conn <path>/beacon fd=3 AF_INET 10.90.95.53:53
🧷 udp-conn <path>/beacon sport=55330
📨 udp-send <path>/beacon 10.90.90.154:55330 -> 10.90.95.53:53 bytes=27
📦 udp-pkt <path>/beacon 10.90.95.53:53 -> 10.90.90.154:55330 len=43
📬 udp-recv <path>/beacon 10.90.90.154:55330 -> 10.90.95.53:53 bytes=43
🧦 sys-sock <path>/beacon AF_INET STREAM TCP
🔌 sys-conn <path>/beacon fd=4 AF_INET 127.0.0.1:8080
🔗 tcp-conn <path>/beacon 127.0.0.1:55746 -> 127.0.0.1:8080
📤 tcp-send <path>/beacon 127.0.0.1:55746 -> 127.0.0.1:8080 bytes=776
📥 tcp-recv <path>/beacon 127.0.0.1:55746 -> 127.0.0.1:8080 bytes=38
🧹 tcp-close <path>/beacon 127.0.0.1:55746 -> 127.0.0.1:8080
Quick summary of the lines:
🚀 execfromperf_events- tetragon captures process execution with credential context and parent process name🧦 sys-sockfromsys_socket- socket creation with family/type/protocol🔌 sys-connfromsys_connect- connect syscall with destination🧷 udp-connfromudp_connect- UDP socket “connected”📨 udp-sendfromudp_sendmsg- UDP send with addresses and payload length📦 udp-pktfromskb_consume_udp- catches UDP packets even when userspace doesn’t callrecvmsg- some applications use mmap’d rings or async I/O that bypass the standard recv syscalls📬 udp-recvfromudp_recvmsg- UDP receive with addresses and length🔗 tcp-connfromtcp_connect- TCP socket requested to be connected📤 tcp-sendfromtcp_sendmsg- TCP send with addresses and length📥 tcp-recvfromtcp_recvmsg- TCP receive with addresses and length🧹 tcp-closefromtcp_close- TCP connection closing
We now see the full DNS query lifecycle (socket create, connect, send query, receive response) and the full TCP beacon lifecycle. For the standard socket paths used here, we now capture the full network lifecycle with useful context. Socket creation, connect, send, receive, and close events are all captured.
Here’s what Tetragon captures during Glimmer’s DNS query phase when it uses a normal socket and UDP connection. Glimmer uses direct assembly syscalls, so the libc uprobes don’t fire - only the kernel kprobes do:
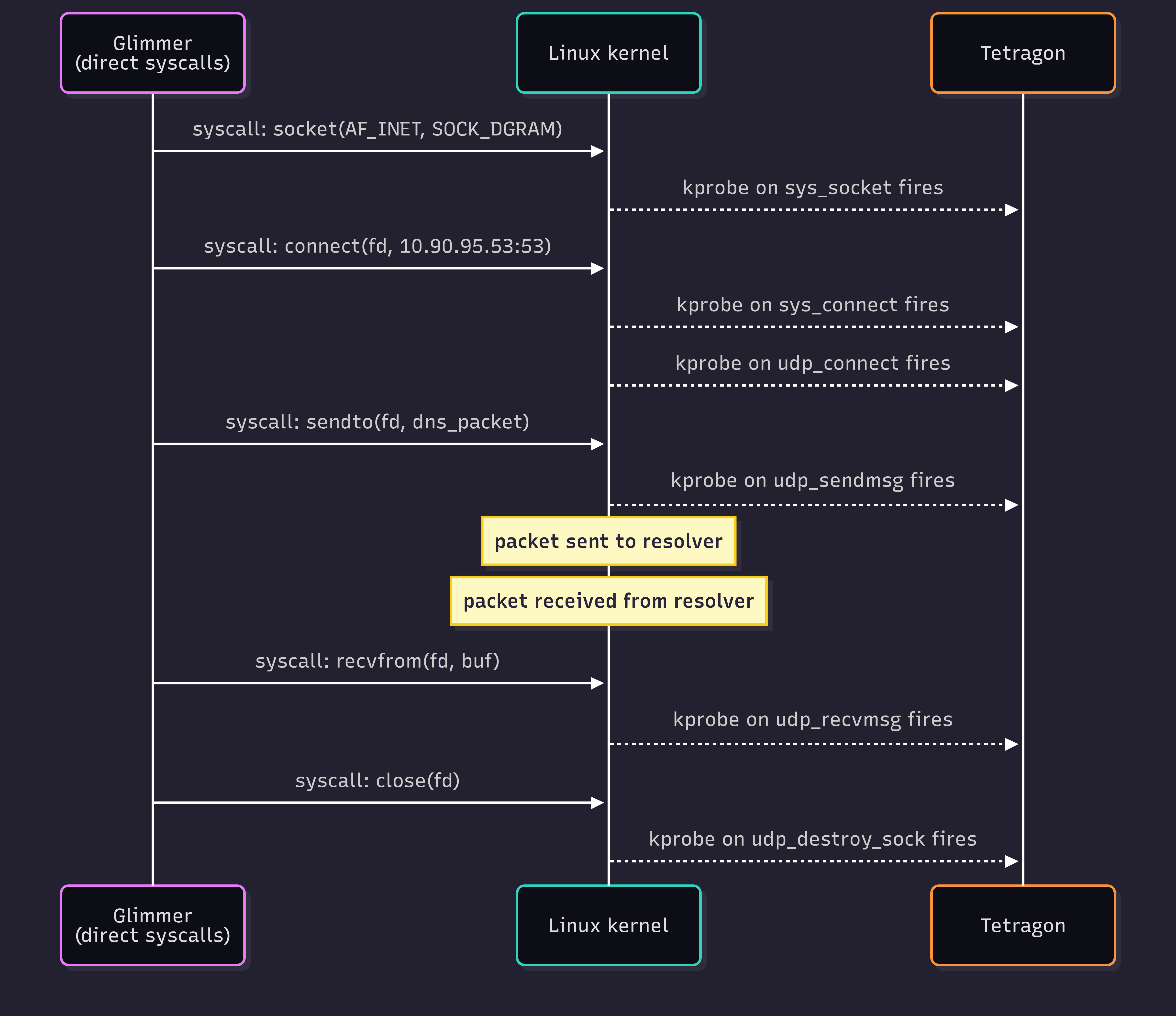
Which means Glimmer needs another iteration. How else can we get our traffic out? What if the beacon doesn’t use standard sockets at all?
The Dispatch Tree
Before moving on to the next Glimmer iteration, it’s worth understanding what’s actually happening when a kprobe fires. When userspace calls write(fd, buf, len) on a normal TCP socket (AF_INET, SOCK_STREAM), the kernel dispatches through a chain of functions before the bytes hit the wire. On my workstation:

Each of those functions is a potential kprobe target. Hooking at tcp_sendmsg (highlighted) catches TCP traffic regardless of which userspace call initiated it - write, send, sendto, sendmsg, or a direct assembly syscall all converge on tcp_sendmsg for TCP sockets. That convergence is what makes kprobes more reliable than uprobes for catching network activity: attackers can avoid libc, but they can’t avoid the kernel’s dispatch.
But tcp_sendmsg only catches TCP. The kernel’s dispatch logic for network sends isn’t a single path, it’s a tree. At sock_sendmsg, the kernel branches based on the socket’s protocol family, then branches again based on the transport protocol:
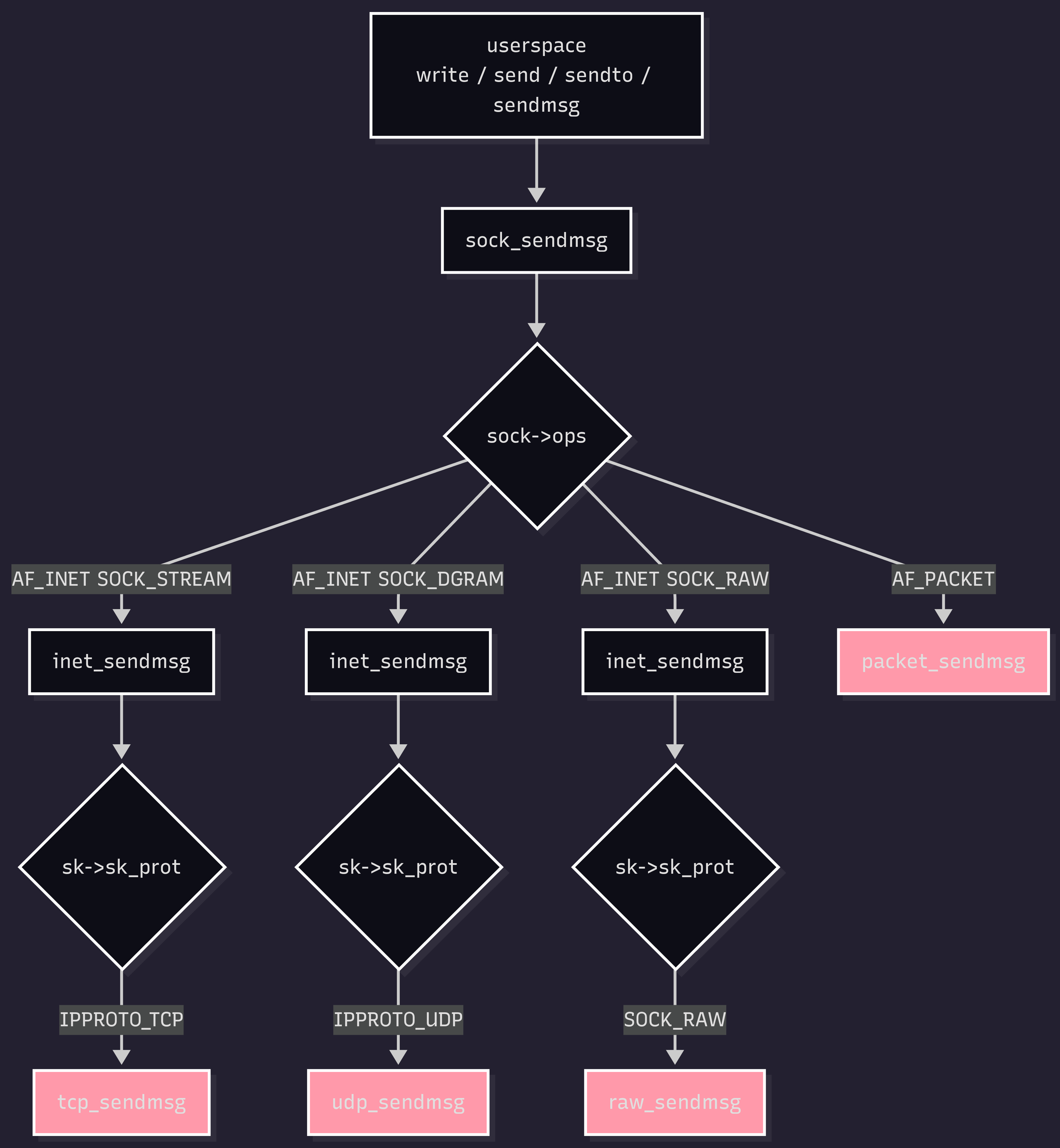
Each highlighted function is a separate kprobe target. tcp_sendmsg catches TCP only. udp_sendmsg catches UDP only. raw_sendmsg catches AF_INET raw sockets. packet_sendmsg catches AF_PACKET sockets - an entirely different family that bypasses the normal IP path.
Hooking at sock_sendmsg would catch everything in this diagram, but at a cost - you lose access to protocol-specific context (TCP sequence numbers, UDP lengths, etc.). Hooking at each leaf gives you that context but requires covering every branch.
Most “normal” traffic will get captured by hooks on tcp_sendmsg and udp_sendmsg, but there are other paths including raw_sendmsg and packet_sendmsg too. Glimmer is about to explore those blind spots.
The above diagrams are simplified, there are additional steps not shown (like VFS layer details, skb handling, qdisc processing on egress, etc) but the essential structure is correct.
Below the Standard Socket Layer
Glimmer’s next iteration sheds standard socket abstractions. Two new test binaries explore different depths below the normal socket layer:
raw-test-af-inet: uses AF_INET with SOCK_RAW and IPPROTO_TCP with the IP_HDRINCL option set. This lets the binary construct its own IP and TCP headers byte-by-byte and send them via a raw IP socket. The kernel still handles Ethernet framing, routing, and ARP but we supply most of L3/L4.
raw-test-af-packet: uses AF_PACKET with SOCK_DGRAM. This operates one layer lower. The kernel constructs the Ethernet header from a sockaddr_ll struct we provide (destination MAC, interface index, protocol), and everything from IP upward is our responsibility. We construct the IP header, the UDP header, compute checksums, and the kernel puts it on the wire as-is.
Both approaches bypass the kernel’s normal TCP/UDP state machines. Neither performs a TCP handshake, ARP resolution by IP, or automatic checksum computation. These alternatives are not used frequently and provide a very high-signal opportunity to log and alert (and/or prevent) when seen. These are typically associated with network scanners (nmap), packet crafters (scapy), ping (a whole rabbit hole), or sometimes malware doing L3/L2 tricks or hiding from more commonly observed paths.
Running against the extended policy
Running raw-test-af-inet against our extended policy:
🚀 exec bash -> <path>/raw-test-af-inet 🛑 CAP_SYS_ADMIN
🧦 sys-sock <path>/raw-test-af-inet AF_INET RAW TCP 🛑 CAP_SYS_ADMIN
💥 exit <path>/raw-test-af-inet 0 🛑 CAP_SYS_ADMIN
Glimmer actually sent a SYN here, not shown. A full HTTP POST version is in progress. We catch the socket creation event, but nothing else. The binary doesn’t call connect(), so tcp_connect doesn’t fire. It doesn’t call write() or send(), so tcp_sendmsg doesn’t fire either. The packet goes out through sendto which goes through raw_sendmsg (one of the parallel branches from the dispatch tree), which we’re not hooking yet.
Worth noting, both of these techniques require root or CAP_NET_RAW. In my lab the process also had CAP_SYS_ADMIN, which is what is displayed in these examples. Tetragon captures the increased effective capabilities in this run.
Running raw-test-af-packet:
🚀 exec /bin/bash -> <path>/raw-test-af-packet 🛑 CAP_SYS_ADMIN
🧦 sys-sock <path>/raw-test-af-packet AF_PACKET DGRAM proto=8 🛑 CAP_SYS_ADMIN
🧦 sys-sock <path>/raw-test-af-packet AF_NETLINK RAW|CLOEXEC default 🛑 CAP_SYS_ADMIN
💥 exit <path>/raw-test-af-packet 0 🛑 CAP_SYS_ADMIN
This binary actually sent out a DNS request not shown. Same as above - socket creation fires, but nothing else. The packet goes out through packet_sendmsg, also not hooked, also a parallel branch.
The additional AF_NETLINK socket is coming from using the libc helper getifaddrs(). That will get replaced with more sophisticated techniques in the next round.
Neither binary would be caught by a detection system relying on the “normal” AF_INET TCP/UDP hooks. Both binaries generate traffic on the wire that looks like legitimate DNS/etc depending on what they constructed. An investigator looking only at tcpdump output or upstream network traffic wouldn’t see anything unusual (well, maybe for a single UDP packet, but that could be an entire series on it’s own). The payloads can appear protocol-shaped on the wire, but the key gap here is that endpoint visibility tied only to normal TCP/UDP hooks misses the send path entirely.
Closing the gaps
Adding three more kprobes:
raw_sendmsg- labeled as🪤 raw-sendbelow, catches AF_INET SOCK_RAW sendspacket_sendmsg- labeled as🧪 pkt-sendbelow, catches AF_PACKET sends__dev_queue_xmit- labeled as🚚 dev-qxmitbelow, most kernel-managed egress paths discussed converge here
Running the test binaries again. First, raw-test-af-packet:
🚀 exec bash -> <path>/raw-test-af-packet 🛑 CAP_SYS_ADMIN
🧦 sys-sock <path>/raw-test-af-packet AF_PACKET DGRAM proto=8 🛑 CAP_SYS_ADMIN
🧦 sys-sock <path>/raw-test-af-packet AF_NETLINK RAW|CLOEXEC default 🛑 CAP_SYS_ADMIN
🚚 dev-qxmit <path>/raw-test-af-packet 10.90.90.154:60703 -> 10.90.95.53:53 udp len=68 🛑 CAP_SYS_ADMIN
🧪 pkt-send <path>/raw-test-af-packet AF_PACKET SOCK_DGRAM bytes=54 🛑 CAP_SYS_ADMIN
💥 exit <path>/raw-test-af-packet 0 🛑 CAP_SYS_ADMIN
Next raw-test-af-inet:
🚀 exec bash -> <path>/raw-test-af-inet 🛑 CAP_SYS_ADMIN
🧦 sys-sock <path>/raw-test-af-inet AF_INET RAW TCP 🛑 CAP_SYS_ADMIN
🪤 raw-send <path>/raw-test-af-inet AF_INET proto=TCP bytes=40 🛑 CAP_SYS_ADMIN
🚚 dev-qxmit <path>/raw-test-af-inet 127.0.0.1:45000 -> 127.0.0.1:8080 tcp len=54 🛑 CAP_SYS_ADMIN
💥 exit <path>/raw-test-af-inet 0 🛑 CAP_SYS_ADMIN
Both test binaries are now caught at send time. The raw-send event includes the socket context and bytes sent. The pkt-send event includes the interface, protocol (ETH_P_IP), and packet bytes. The dev-qxmit events capture the connection tuple and protocol information.
For af_packet_test specifically, the detection story is richer. The test binary has to do significant work before it can send:
- Read
/proc/net/routeto determine the path to our destination network - Read
/proc/net/arpto determine the MAC address of the gateway - Call
libc::if_nametoindexto determine the interface index - Call
libc::getifaddrsto determine our local ip address - Create
AF_PACKETsocket - Construct the entire TCP/IP packet bit-by-bit including the ethernet frame
- Call
packet_sendmsgto deliver the package
Each of those is a weak signal alone - normal software reads /proc/net occasionally, normal software calls getifaddrs. But a single process reading /proc/net/route AND /proc/net/arp AND opening an AF_PACKET socket within a few seconds is distinctively for raw packet crafting. This is where single-event detection gives way to combination detection, and it’s the shape of everything that follows.
Worth noting, this is only showing the transmit, not the receive. AF_NETLINK poses as many if not more challenges on the receive side as it does on the transmit side. This will be explored in-depth in a future post exploring integrating these channels for stable reliable communications in Glimmer.
One more bypass
There is another parallel path to __dev_queue_xmit that bypasses qdisc and tc entirely. Setting the sockopt PACKET_QDISC_BYPASS on an AF_PACKET socket flips an internal check inside packet_sendmsg so that the packet exits via __dev_direct_xmit instead of going through __dev_queue_xmit and the qdisc/tc layer.
I added functionality to glimmer and af_packet_test --bypass to test this and see what shows up in our current Tetragon detection. Running af_packet_test again with –bypass enabled:
🚀 exec sudo -> <path>/raw-test-af-packet --bypass 🛑 CAP_SYS_ADMIN
🧦 sys-sock <path>/raw-test-af-packet AF_PACKET DGRAM proto=8 🛑 CAP_SYS_ADMIN
🧦 sys-sock <path>/raw-test-af-packet AF_NETLINK RAW|CLOEXEC default 🛑 CAP_SYS_ADMIN
🧪 pkt-send <path>/raw-test-af-packet AF_PACKET SOCK_DGRAM bytes=54 🛑 CAP_SYS_ADMIN
💥 exit <path>/raw-test-af-packet 0 🛑 CAP_SYS_ADMIN
We still capture the pkt-send line because of our hook on packet_sendmsg, however we no longer capture the dev-qxmit line. If the only egress hook had been __dev_queue_xmit, this would have been a complete miss. The per-family hook upstream is what kept it visible.
This introduces two more hooks that are high value:
__dev_direct_xmit- labeled as🛻 dev-xmitbelow, catches the AF_PACKET QDISC_BYPASS pathsys_setsockopt- labeled as🪛 sock-optbelow, catches socket options being set that are unusual/suspicious
🚀 exec sudo -> <path>/raw-test-af-packet --bypass 🛑 CAP_SYS_ADMIN
🧦 sys-sock <path>/raw-test-af-packet AF_PACKET DGRAM proto=8 🛑 CAP_SYS_ADMIN
🧦 sys-sock <path>/raw-test-af-packet AF_NETLINK RAW|CLOEXEC default 🛑 CAP_SYS_ADMIN
🪛 sock-opt <path>/raw-test-af-packet fd=3 SOL_PACKET/PACKET_QDISC_BYPASS 🛑 CAP_SYS_ADMIN
🛻 dev-xmit <path>/raw-test-af-packet 10.90.90.154:16739 -> 10.90.95.53:53 udp len=68 🛑 CAP_SYS_ADMIN
🧪 pkt-send <path>/raw-test-af-packet AF_PACKET SOCK_DGRAM bytes=54 🛑 CAP_SYS_ADMIN
💥 exit <path>/raw-test-af-packet 0 🛑 CAP_SYS_ADMIN
The kernel was doing a lot for us
When I first wrote af_packet_test, I assumed the hard part was the kprobe coverage. The hard part was reconstructing all the things the kernel normally does for you. A packet sent via a standard TCP or UDP socket goes through several kernel subsystems, each of which adds something essential:
Checksum computation: TCP and UDP headers include checksums covering the transport header, payload, and a pseudo-header containing source/dest IP and protocol. The kernel computes these automatically, AF_PACKET requires you to compute them yourself. Missing or incorrect checksums cause pf, iptables, and some middleboxes to silently drop the packet.
IP identification field randomization: every IP packet has a 16-bit ID used to identify fragments. The kernel generates these with randomization, a hand-crafted packet using a fixed ID (like
0x1234) triggers dedup heuristics in stateful firewalls.Routing and ARP resolution: normally the kernel looks up the destination IP, determines the next hop, queries ARP for the next hop’s MAC, and constructs the Ethernet frame. AF_PACKET requires you to do all of that yourself - read the routing table, find the correct gateway, look up its MAC in the ARP cache.
Interface selection: the kernel chooses which interface to use based on the routing table. AF_PACKET requires you to specify the interface index explicitly.
Source MAC insertion: one thing the kernel does keep for you with SOCK_DGRAM (but not SOCK_RAW) - the source MAC of the outbound interface is filled in automatically. The destination MAC is your responsibility.
IP header construction: every byte from version/IHL to the destination IP is up to you. Wrong total length field, wrong protocol number, wrong flags - any of these cause the packet to be dropped somewhere, often silently.
There’s a useful detection insight hiding here. Legitimate software that uses AF_PACKET is almost always using well-tested libraries (libpcap, scapy, or their equivalents) that handle all of this correctly. A hand-crafted packet with a zero UDP checksum, a re-used fixed IP ID, or a destination MAC of all zeros is either a bug in unusual software or the fingerprint of someone reimplementing networking poorly (a.k.a. me 4 hours ago). Detection rules that flag “malformed but technically valid” packets at the firewall or switch level catch the mistakes, and those rules cost very little to run.
Add to that the syscall and file-access signals on the endpoint (reading /proc/net/route, opening AF_NETLINK for interface queries, opening AF_PACKET socket), and the combination is very challenging to avoid unless you’re writing high-quality custom tooling.
Combination detection
The af_packet_test binary produces a specific signature across multiple Tetragon events. If we capture reads to /proc/net/route and /proc/net/arp:
📖 fs-read <path>/raw-test-af-packet /proc/1180630/net/route 🛑 CAP_SYS_ADMIN
🧦 sys-sock <path>/raw-test-af-packet AF_NETLINK RAW|CLOEXEC default 🛑 CAP_SYS_ADMIN
📖 fs-read <path>/raw-test-af-packet /proc/1180630/net/arp 🛑 CAP_SYS_ADMIN
🧦 sys-sock <path>/raw-test-af-packet AF_PACKET DGRAM proto=8 🛑 CAP_SYS_ADMIN
🚚 dev-qxmit <path>/raw-test-af-packet 10.90.90.154:39227 -> 10.90.95.53:53 udp len=68 🛑 CAP_SYS_ADMIN
🧪 pkt-send <path>/raw-test-af-packet AF_PACKET SOCK_DGRAM bytes=54 🛑 CAP_SYS_ADMIN
Individual events vary in quality of signal. /proc/net/route is read by normal software occasionally. AF_NETLINK sockets are common (systemd uses them extensively). AF_PACKET sockets exist for legitimate reasons (tcpdump, wireshark, DHCP clients, some VPN software).
But the combination of a single process, within a few seconds, reading /proc/net/route, opening an AF_NETLINK socket, opening an AF_PACKET socket, and calling packet_sendmsg - is extremely rare in normal operation. Tcpdump and wireshark match this pattern but their binaries are known and whitelistable. A previously-unknown binary matching this combination is essentially always worth investigating.
Alerts
I have started adding tags to individual events I want to alert on immediately. While many calls require correlation across multiple conditions before alerting, some are immediately suspicious/anomalous. I have added an alert on calls to __dev_direct_xmit with sockets setting PACKET_QDISC_BYPASS. The tags and the alert message are all added to the Tetragon json log. I produce lines like this in the tetra-pretty script:
🚨 ALERT qdisc-bypass-transmit AF_PACKET qdisc bypass direct network transmission
🛻 dev-xmit <path>/raw-test-af-packet 10.90.90.154:16739 -> 10.90.95.53:53 udp len=68 🛑 CAP_SYS_ADMIN
I am tagging alerts in terms of severity and confidence. This is a high-confidence medium-severity alert on my workstation - there is no legitimate software calling __dev_direct_xmit.
I stream these logs to both Loki and Wazuh and I can write rules to alert or take action on them immediately. In the future I will be exploring writing a local security agent that can watch the event stream in real-time and take some actions on its own - kill processes, quarantine binaries, collect forensics, react faster. The external systems can take much more meaningful action (quarantine the node, take an image of the volume, research other anomalies across my environment, etc.) but they are largely designed to preserve the integrity and functioning of the environment as a whole. The individual node (or my workstation in this case) needs capabilities of its own, it can react faster, and it can keep working even if those external systems are unreachable.
Every egress path in one picture
Pulling all the egress paths into one view shows which hooks cover what, and where netfilter does and doesn’t get a vote.
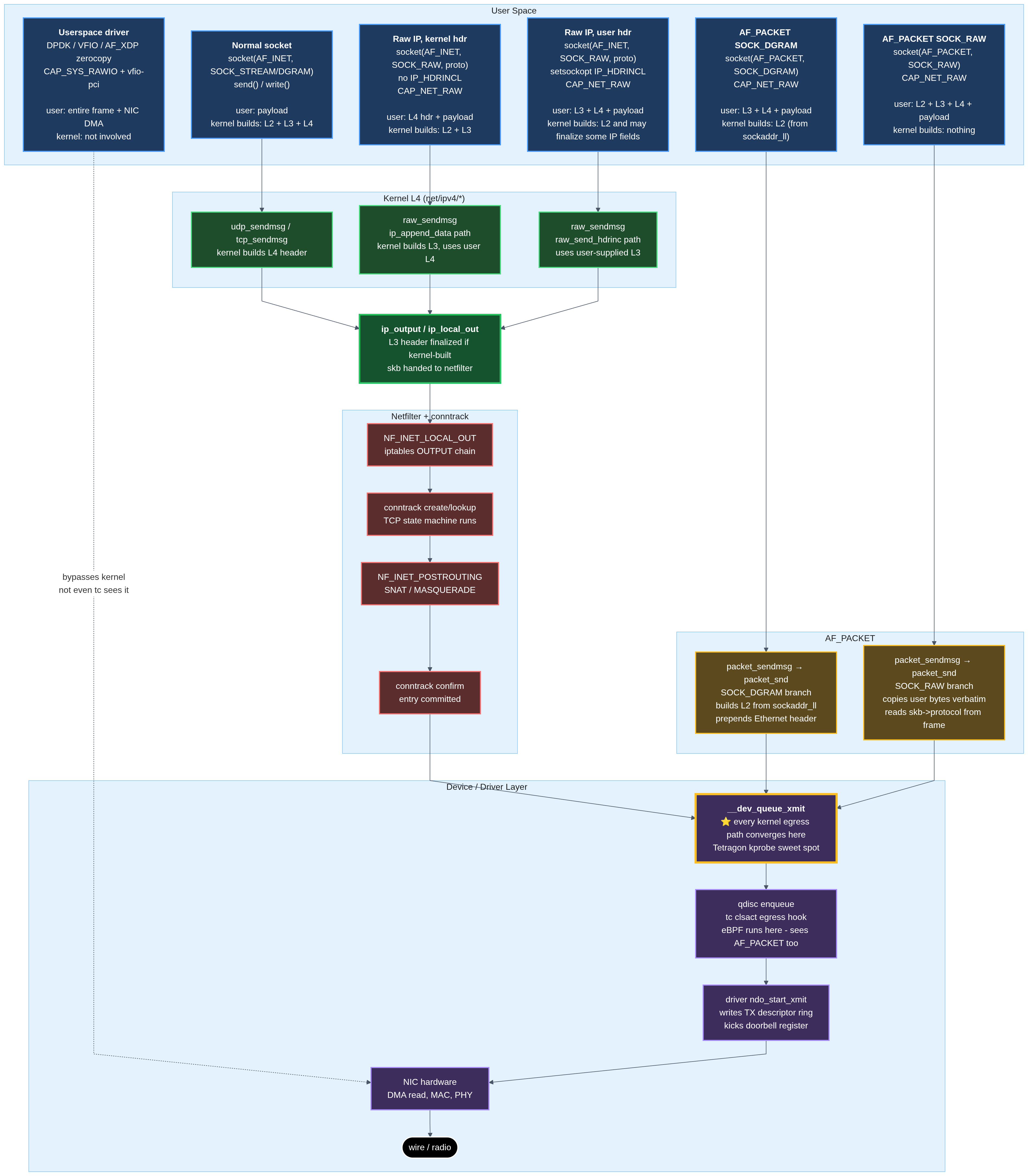
Pulling it together, here’s the coverage matrix for the techniques explored in this post:
| Technique | Dispatched via | Uprobes | Stock kprobes | Extended kprobes | Needed for full picture |
|---|---|---|---|---|---|
| libc TCP connect/send | tcp_sendmsg -> __dev_queue_xmit | ✓ | ✓ | ✓ | - |
| Asm syscall UDP | udp_sendmsg -> __dev_queue_xmit | ✗ | ✓ | ✓ | - |
| AF_INET SOCK_RAW (IP_HDRINCL) | raw_sendmsg -> __dev_queue_xmit | ✗ | ✗ | ✓ | setsockopt(IP_HDRINCL) |
| AF_PACKET SOCK_DGRAM/RAW | packet_sendmsg -> __dev_queue_xmit | ✗ | ✗ | ✓ | - |
| AF_PACKET + QDISC_BYPASS | packet_sendmsg -> __dev_direct_xmit | ✗ | ✗ | ✓ | __dev_direct_xmit + setsockopt(PACKET_QDISC_BYPASS) |
| AF_PACKET PACKET_MMAP TX_RING | (not caught) | ✗ | ✗ | ✗ | TC |
Caveats and What’s Still Missing
packet_sendmsg and raw_sendmsg close specific gaps, but there are others worth naming so the post doesn’t leave you with a false sense of completeness.
PACKET_MMAP with TX_RING
af_packet_test uses the ordinary sendto() path on an AF_PACKET socket, which is why packet_sendmsg catches it. AF_PACKET also supports a higher-performance mode called PACKET_MMAP with a transmit ring (TX_RING). In this mode, userspace and the kernel share a memory-mapped ring buffer. The application writes packets into the ring and signals the kernel to transmit them, and the kernel reads them directly from the shared memory. No sendmsg-family call is involved.
This is the transmission method used by high-performance packet generators and by some sophisticated tooling. packet_sendmsg doesn’t fire for TX_RING transmissions because the kernel never enters that function.
Catching TX_RING traffic requires hooking lower in the stack - tc egress or lower driver/NIC-path instrumentation. Both are more invasive than kprobes and add meaningful work. This post is mostly focused on egress blind spots. Ingress coverage is a separate question, and that is where XDP becomes much more relevant. I will be exploring both in a future post.
io_uring
Linux’s io_uring subsystem lets applications submit I/O operations via shared ring buffers, bypassing traditional syscall entry points for read, write, send, recv, etc. An application using io_uring for network I/O bypasses classic syscall-entry monitoring. Whether deeper socket-path kprobes still fire depends on the operation and hook point.
Hooks on io_uring_submit_sqe and related functions can catch io_uring operations, but interpreting them correctly requires understanding the ring buffer structure, which is more involved than reading syscall arguments.
I will be exploring io_uring further as a practical evasion surface and methods for detection. This requires specialized code when ordinary syscalls work fine and arguably blend in better with legitimate traffic but I want to understand it.
Userspace TLS visibility
Everything in this post operates below the application layer. A beacon doing HTTP POST over HTTPS goes through tcp_sendmsg with encrypted bytes in the payload - we see the connection, the destination, the byte count, but not the plaintext request.
For plaintext visibility, uprobes on TLS library functions (SSL_write in OpenSSL, equivalents in BoringSSL/NSS/rustls/GnuTLS) capture data before encryption or after decryption. Coverage varies by library, statically-linked TLS (common in Go binaries and Chromium-based browsers) requires hooking at offsets inside the specific binary rather than a shared library, which means re-discovering offsets after every update.
This will also be its own post. Endpoint-level TLS inspection is essential as ECH, QUIC, and certificate pinning reduce what’s visible on the wire.
Detection stack completeness
The Tetragon policies in this post cover most of the common paths for network activity on a Linux endpoint. They don’t cover every possible evasion, and no endpoint observability system ever will. The cost-benefit curve favors the attacker for the most exotic techniques.
I will be exploring behavioral analysis as a detection method for some of the remaining gaps in future posts.
What I Took Away From This
A few observations from working through this in my own bespoke infrastructure.
Hooks that are high signal to noise
The hooks I added without much hesitation were the ones where the cost-benefit tradeoff felt heavily one-sided in my favor. tcp_sendmsg catches every TCP send on the machine through normal channels and costs the kernel essentially nothing. It provides additional context (process, user, etc) to the connection that network monitoring etc can not obtain independently.
packet_sendmsg and raw_sendmsg are similar. These are extremely rare events outside of a few specific well-known tools like tcpdump, wireshark, DHCP clients, some VPN software, nmap. The binaries/behavior that use them legitimately are easy to match and exclude. Avoiding it while using an AF_PACKET socket would require implementing something like PACKET_MMAP with TX_RING, which is a real project.
A reasonable question is if __dev_queue_xmit is the kernel’s chokepoint for packet egress and has access to the full skb context, why not just hook there and filter by call path? Technically you can, walking the stack to find the callsite works with some overhead. eBPF supports stack trace capture via bpf_get_stack(), and a hook at __dev_queue_xmit with call-site filtering would catch everything reaching the wire regardless of which layer initiated it.
The reason I’m not doing this as the primary approach is the per-protocol context is cleaner at the higher hooks, the event volume is reasonable without needing heavy filtering, and Tetragon’s YAML policy language handles the higher-level hooks cleanly. Writing raw BPF programs for that level of control is possible and something I will explore soon with aya.
What I’m considering is a secondary hook at __dev_queue_xmit specifically as an “anomaly detector” - fire only when packets reach the wire through a path my higher-level hooks don’t cover. That way the primary detection uses the ergonomic layer, and the lower hook serves as a “trust but verify” check for the paths I haven’t thought of yet. I haven’t built this yet, it’s on the list.
The hooks I’m less sure about are the ones where the asymmetry is closer to even. Hooking SSL_write in libc is easy, hooking it in Chromium’s statically-linked BoringSSL is technically straightforward, but keeping it working across browser updates requires ongoing maintenance as binary offsets shift. An attacker who wants to avoid it can statically link rustls instead, which is not especially hard. The cost on my side accumulates with every browser update, the attacker’s cost is a one-time decision. I’m still thinking about whether the visibility into plaintext traffic is worth that ongoing maintenance for my situation, or whether I’d rather invest the same effort into something with better asymmetry.
Other people working in other environments might weigh the same hooks differently, or might care about entirely different dimensions (performance overhead, kernel version portability, what their SIEM can ingest, etc).
The abstraction cliff I hit
Building the AF_PACKET test binary took more work than I expected. Not because AF_PACKET itself is complicated, but because each thing the kernel normally does turned into something I had to reimplement: routing, ARP lookup, MAC resolution, checksum computation, IP ID randomization, interface selection. Each piece is a small amount of code in isolation. The pile of all of them adds up, implementing it into a working app like Glimmer and not just a proof-of-concept is even more work.
Standard sockets work and they blend in with legitimate traffic. AF_PACKET seems to have specific use-cases. In practice, it may be less-desirable to an attacker in a heavily-monitored environment as this will stand out more than almost anything else does, even though it bypasses iptables/netfilter/conntrack and is technically powerful.
What I’m thinking about retention
Historically, my mindset is to capture and log everything and persist it forever. That worked when I was storing things like syslog data, auditd logs, application logs, firewall logs, even observability data like Pyroscope continuous system profiles. eBPF is capable of collecting a firehose of valuable data from each endpoint, but the value of that data has a different lifetime and purpose.
My current direction is something like: cheap in-kernel observation with narrow filtering, richer correlation in a userspace agent close to the endpoint (Vigil or something like it), and only high-confidence events or summarized forensic data shipped to centralized log infrastructure. Volume lives at the endpoint where I can filter aggressively and signal is what leaves the endpoint.
Something that helped me think about this more clearly is that real-time consumers of the event stream don’t actually need events to be persisted at all. Tetragon exposes its events via a gRPC interface, and a subscriber connected to that stream gets events as they happen. If the agent doing correlation is already consuming the stream in real-time, persistence isn’t serving the detection goal - detection has already happened by the time a persisted event would be queried. That shifts persistence to a forensic question, how much disk or memory am I willing to spend so I can look backward when investigating something.
For the specific question of “how much of the kprobe firehose do I persist,” I’m currently leaning toward a tiered approach: a small hot tier for real-time alerting, a medium warm tier for a few hours-days of correlation windows, and either a cold tier for forensics or delegating that to whatever the centralized pipeline already stores. I haven’t fully built this out yet - it’s on the list.
| Event class | Where stored | Retention | Notes |
|---|---|---|---|
| exec events | Wazuh + Loki | 90 days | every binary execution |
| privilege changes | Wazuh + Loki | 1 year | setuid/setgid/capset |
| BPF program loads | Wazuh + Loki + alert | 1 year | very rare, high signal |
| socket creation | Loki | 30 days | moderate volume |
| tcp_sendmsg sock | Loki | 7 days | high volume, flow-like |
| udp_sendmsg sock | Loki | 7 days | DNS traffic mostly |
| raw packet bytes | Local only, rotated | minutes | enabled during investigations |
| DNS queries (zeek) | Loki | 90 days | answers from wire, not endpoint |
| TLS SNI (suricata) | Loki | 90 days | TLS handshake metadata, low volume |
I’ve also started thinking about retention not as one question but several - data for future investigations, data for updating detection models, data for audit compliance. These have very different retention profiles and might not all belong in the same tier.
The constraint I keep coming back to
The thing that keeps shaping my choices is that attention is finite and every event I capture has to justify its place against how much attention it will eventually demand. Not just my attention - correlation rules, alerting thresholds, LLM-based triage, and whatever sits downstream of the event stream. Each consumer has a limited amount of attention to spend.
For me, this turns into every hook I add has to answer what decision it enables and at what cost. Hooks that drive real-time alerts need to be high-confidence. Hooks that produce context for investigation can afford to be lower-signal because they only get looked at when something specific is being investigated. Hooks that don’t fit either category are probably just noise I’m paying to collect.
Building a model of what is normal also requires thinking about what data feeds that model. Ingest the firehose directly? Summarize with a local model first and ship the summaries? Or something in between, like selective ingestion to a central training system that produces updated models for local agents to use. I don’t have a settled answer here yet.
One thing I’m thinking about as an eBPF optimization is right now, if I want to detect a behavior that depends on 5 conditions, I log all 5 events every time they occur and evaluate the combination downstream. That’s great for audit trail but noisy for operations. With more sophisticated eBPF programs, I could write multi-step conditional logic in-kernel — only start emitting events after 2-3 conditions have been met, and take disruptive action at 4-5. Volume reduces dramatically while detection quality stays the same or improves.
This approach is what I’ve settled on for now. It will probably shift as tooling improves. Local LLM agents capable of continuously analyzing a full event firehose change the economics of what “too much data” means. I’ll write about that direction as it develops.
Where this leaves me
Tetragon caught some things. Extending it caught more things. Iterating against Glimmer showed some evasions were caught by the extended policy and some weren’t. Each iteration revealed new hook points, new evasion techniques, new gaps.
The matrix of techniques is wider than I can keep track of by hand, and the iteration loop is slow when I’m manually running each test binary and checking output. Outside of this series, I will be building a tool that manages the matrix, runs the tests, and verifies the detection coverage end-to-end.
This is part 3 of an ongoing series. Part 4 will cover D-Bus as an information collection surface - what a process can learn about the system, the user, and other applications over the session and system buses, and what that looks like through Tetragon.